Every so often, someone suggests that GitHub would be a great way to manage legislation. Usually, we roll our eyes at the naïve suggestion and that is that.
However, there are a good many similarities that do deserve consideration. What if the amending process was supported by a tool that, while maybe not GitHub, worked on the same principles?
My company, Xcential, built the amending solution for the California Legislature, using a process we like to call Amendments in Context. With this process, a proposed revision of a bill is drafted and then the amendments necessary to produce that revision are extracted as an amendment document. That amendment document, which really becomes an enumeration of proposed changes in a report, is then submitted to the committee for approval. If approved, the revised document that was drafted earlier then becomes the next official version of the bill. This process differs from the traditional process in which an amendment document is drafted, itemizing changes to be made. When the committee approves the amendments, there is a mad rush, usually overnight, to implement (or execute) those amendments to the last version in order to produce the next version. Our Amendments in Context automated approach is more accurate and largely eliminates the overnight bottleneck of having to execute approved amendments before the start of business the following day.
Since implementing this system for California, we’ve been involved in a number of other jurisdictions and efforts that deal with the amending process. This has given us quite a good perspective on the various ways in which bill amendments get handled.
As software developers ourselves, we’ve often been struck by how similar the bill amendment process is to the software development process — the very thing that invariably leads to the suggestion that GitHub could be a great repository for legislation. With this all in mind, let’s compare and contrast the bill amending process with the software development process using GitHub.
(We’ll make suitable procedural simplifications to keep the example clear)
| BILL AMENDING PROCESS |
SOFTWARE ENHANCEMENT PROCESS |
| Begin a proposed amendment |
Begin a proposed enhancement |
| Create a copy of the last version of a bill. In the U.S. and other parts of the world that still use page and line numbers, cleverly annotated page and line number information from the last publication must be included. This copy will be modified to reflect the proposed changes. |
Create a new software branch. This branch will be modified to implement the proposed enhancement |
| Make the proposed changes using redlining, showing the changes as insertions and deletions. Carefully craft the changes to obey the drafting rules and any political sensitivities regarding how the changes are shown. |
Make the proposed changes to the software — testing and debugging as needed. |
 |
 |
| Generate the amendment |
Prepare to commit |
| The amendment generator examines the redlining (insertions and deletions), carefully grouping changes together to produce a minimized set of amendments. These amendments are expressed in the familiar, at least in the U.S., “on page X, line Y, strike ‘this’ and replace with ‘that'” or something along those lines. (For jurisdictions that don’t use an amendment generator, a manually written amendment document, enumerating the amendments, is the starting point) |
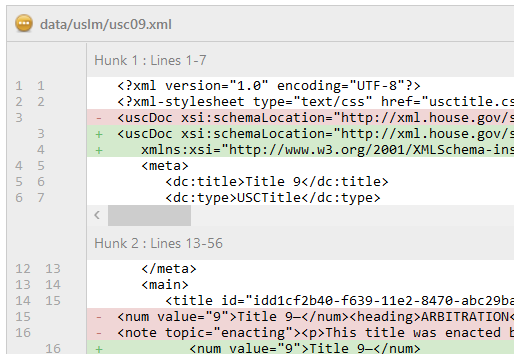
A differencing engine compares the source code with the prior version, carefully grouping changes together to produce a minimized set of hunks. If you use a tool such as SourceTree by Atlassian, these hunks are shown as source code with lines to be removed and lines to be inserted. |
 |
 |
| Save the amendment document alongside the revised bill with redlining |
Commit the changes to GitHub |
| Vote on the amendments |
Submit for review |
| The amendment document goes to committee where it is proposed and then either adopted or rejected. The procedures here may differ, depending on the jurisdiction. In California, multiple competing amendment documents (known as instruction amendments) may be proposed at any one time, but only one can be adopted and it is adopted in whole. Other jurisdictions allow multiple amendment documents to be adopted and individual amendments with any amendment document to be adopted or rejected. |
The review board considers the proposed enhancement and decides whether or not to incorporate them into the next release. They may choose to adopt the entire enhancement or they may choose to adopt only certain aspects of it. |
| Execute the amendment |
Merge into mainline |
| In California, because only single whole amendments can be adopted, executing an adopted amendment is quite easy — the redlined version of the bill simply becomes the next version. However, in most jurisdictions, this isn’t so easy. Instead, each amendment must be applied to a new copy of the bill, destined to become the next version. Conflicts that arise must be resolved following a prescribed set of procedures. |
Incorporating an enhancement into the mainline involves a merge of the enhancement branch into the mainline. If an enhancement is not adopted in whole, then approved changes may be cherry picked. When conflicts between different sets of approved enhancements occur, GitHub requires manual intervention to resolve the issues. This process is generally a lot less formal than resolving conflicts in legislation. |
So, as you can see, there are a lot of similarities between amending a bill and implementing a software enhancement. The basic process is essentially identical. However, the differences lie in the details.
Git is designed specifically for the software development process. The legislative process has quite a different set of requirements and traditions which must be met. It simply isn’t possible to bend and distort the legislative process to fit the model prescribed by Git. However, that doesn’t mean that something like GitHub is out of the question. What if there was a GitHub for Legislation — a tool with an associated repository, modeled after Git and GitHub, specifically designed for managing legislation?
This example shows the power of adopting XML for drafting legislation. With properly designed XML, legislation becomes a vast store of machine-readable information that can meet the 21st century challenges of accuracy, efficiency, and transparency. We’re not just printing paper anymore — we’re managing digital information.