We’re in the process of rebuilding our legislative editor – from the ground up. There are many reasons why we are doing this, which I will leave to my next blog. Today, I want to focus on the most important reason of all – change tracking.

Figure 1: The example above shows non-literal redlining and two different change contexts. An entire bill section is being added – the “action line” followed by quoted text. Rather than showing the entire text in an inserted notation, only the action line is shown. The quoted text reflects a different change context – showing changes relative to the law. In subsequent versions of this bill, the quoted text will no longer show the law as its change context but rather the prior version. It’s complicated!
For us, change tracking is an essential feature of any legislative editor. It’s not something that can be tacked on later or implemented via a customization – it’s a core feature which must be built in to the base editor from the very outset. Change tracking dictates much of the core architecture of the editor. That means taking the time to build in change tracking into the basic DOM structures that we’re building – and getting them right up front. It’s an amazingly complex problem when dealing with an XML hierarchy.
I’ve been asked a number of questions by people that have seen my work. I’ll try to address them here:
Why is change tracking so important? We use change tracking to implement a couple of very important features. First of all, we use it to implement redlining (highlighting the changes) in a bill as it evolves. In some jurisdictions, particularly in the United States, redlining is an essential part of any bill drafting system. It is used to show both how the legislation has evolved and how it affects existing law.
Secondly, we use it to automatically generate “instruction” amendments (floor or committee amendments). First, page and line markers are back-annotated into the existing bill. That bill is then edited to reflect the proposed changes – carefully crafting the edits using track changes to avoid political sensitivities – such as arranging a change so as not to strike out a legislator’s name. When complete, our amendment generator is used to analyze the redlining along with the page and line markers to produce the amendment document for consideration. The cool thing is that to execute the amendments, all we need to do is accept or reject the changes. This is something we call “Amendments in Context” and our customer calls “Automatic Generation of Instruction Amendments” (AGIA).
How is legislative redlining different from change tracking in Word? They’re very similar. In fact, the first time we implemented legislative redlining, we made the mistake of assuming that they were the same thing. What we learned was that legislative redlining is quite a bit more complex. First of all, the last version of the document isn’t the only change context. The laws being amended are another context which must be dealt with. This means that, within the same document, there are multiple original sources of information which must be compared against.
Secondly, legislative redlining has numerous conventions, developed over decades, to indicate certain changes that are difficult or cumbersome to show with literal redlining. These amount to non-literal redlining patterns which denote certain changes. Examples include showing that a paragraph is being merged or split, a provision is being renumbered, a whole bill is being gutted and replaced with all new text, and even that a section, amending law (creating a different change context), is being added to a new version of the bill.
The rules of redlining can be so complex and intricate that they require any built-in change tracking mechanism in an off-the-shelf editor to be substantially modified to meet the need. Our first legislative editor was implemented using XMetaL for the State of California. At first, we tried to use XMetaL’s change tracking mechanisms. These seemed to be quite well thought out, being based on Microsoft Word’s track changes. However, it quickly became apparent that this was insufficient as we learned the art of redlining. We then discovered, much to our alarm, that XMetaL’s change tracking mechanism was transparent to the developer and could not be programmatically altered. Our solution involved contracting the XMetaL team to provide us with a custom API that would allow us to control the change tracking dimension. The result works, but is very complex to deal with as a developer. That’s why they had hidden it in the first place.
Why can’t differencing be used to generate an amendments document? We wondered this as well. In fact, we implemented a feature, called “As Amends the Law” in our LegisWeb bill tracking software using this approach. But, it’s not that straight-forward. First of all, off-the-shelf differencers lack an understanding of the political sensitivities of amendments. What they produce is logically correct, but can be quite politically insensitive. The language of amendments is often very carefully crafted to not upset one side or another. It’s pretty much impossible to relay this to a program that views its task as simply comparing two documents. Put another way, a differencer will show what has changed rather than how it was changed.
Secondly, off-the-shelf differencers don’t understand all the conventions that exist to denote many of the types of amendments that can be made – especially all the non-literal redlining rules. Asking a legislative body to modify their decade’s old customs to accommodate the limitations of the software is an uphill battle.
What approaches to change tracking have you seen? XMetaL’s approach to change tracking is the most useful approach we’ve encountered in XML editors. As I already mentioned, its goal is to mimic the change tracking capabilities of Microsoft Word. It uses XML processing instructions very cleverly to capture the changes – one processing instruction per deletion and a pair for insertions. The beauty of this approach is that it isolates the challenge of change tracking from the document schema – ensuring wide support for change tracking without any need to adapt an existing schema. It also allows the editor to be customized without regard for the change tracking mechanisms. The change tracking mechanisms exist and operate in their own dimension – very nicely isolated from the main aspects of editing. However, when you need to program software in this dimension, the limited programmability and immense complexity becomes a drawback.
Xopus, a web-based editor, tries to mimic XMetaL’s approach – actually using the same processing instructions as XMetaL. However, it’s an apparent effort to tack on change tracking to an existing editor and the result is limited to only tracking changes within text strings. They’ve seemingly never been able to implement a full featured change tracking mechanism. This limits its usefulness substantially.
Another approach is to use additional elements in a special namespace. This is the approach taken by ArborText. The added elements (nine in all), provide a great deal of power in expressing changes. Unfortunately, the added complexity to the customizer is quite overwhelming. This is why XMetaL’s separate change dimension works so well – for most applications.
Our approach is to follow the model established by XMetaL, but to ensure the programmability we need to implement legislative redlining and amendment generation. In the months to come, I will describe all this in much more detail.

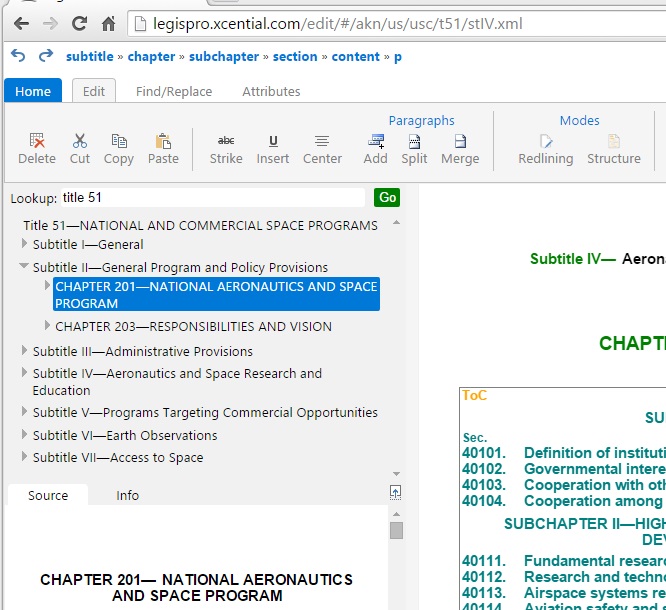
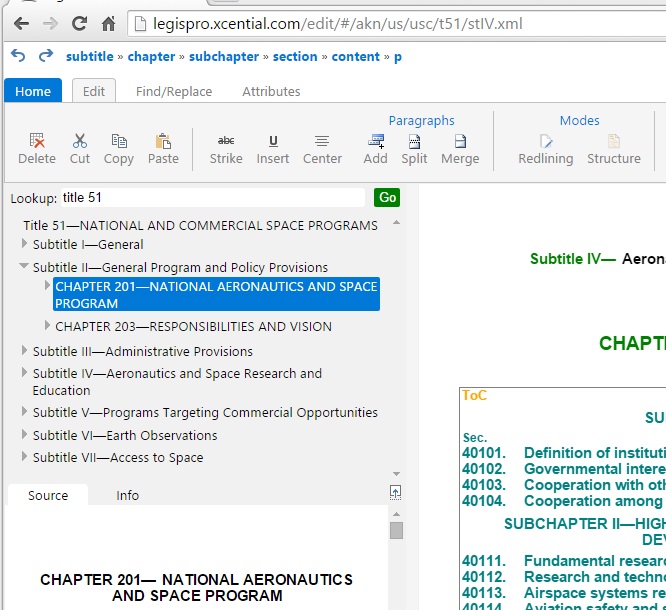
 Take a look at the totally contrived example on the left. It’s admittedly not a real example, it comes from my stress testing of the change tracking facilities. But look at what it does. The red text is a complex deletion that spans elements with little regard to the structure. In our editor, this was done with a single “delete” operation. Try and do this with XMetaL – it takes many operations and is a real struggle – even with change tracking turned off. In fact, even Microsoft Word’s handling of this is less than satisfactory, especially in more recent versions. Behind the scenes, the editor is using the model, derived from the schema, to control this deletion process to ensure that a valid document is the result.
Take a look at the totally contrived example on the left. It’s admittedly not a real example, it comes from my stress testing of the change tracking facilities. But look at what it does. The red text is a complex deletion that spans elements with little regard to the structure. In our editor, this was done with a single “delete” operation. Try and do this with XMetaL – it takes many operations and is a real struggle – even with change tracking turned off. In fact, even Microsoft Word’s handling of this is less than satisfactory, especially in more recent versions. Behind the scenes, the editor is using the model, derived from the schema, to control this deletion process to ensure that a valid document is the result.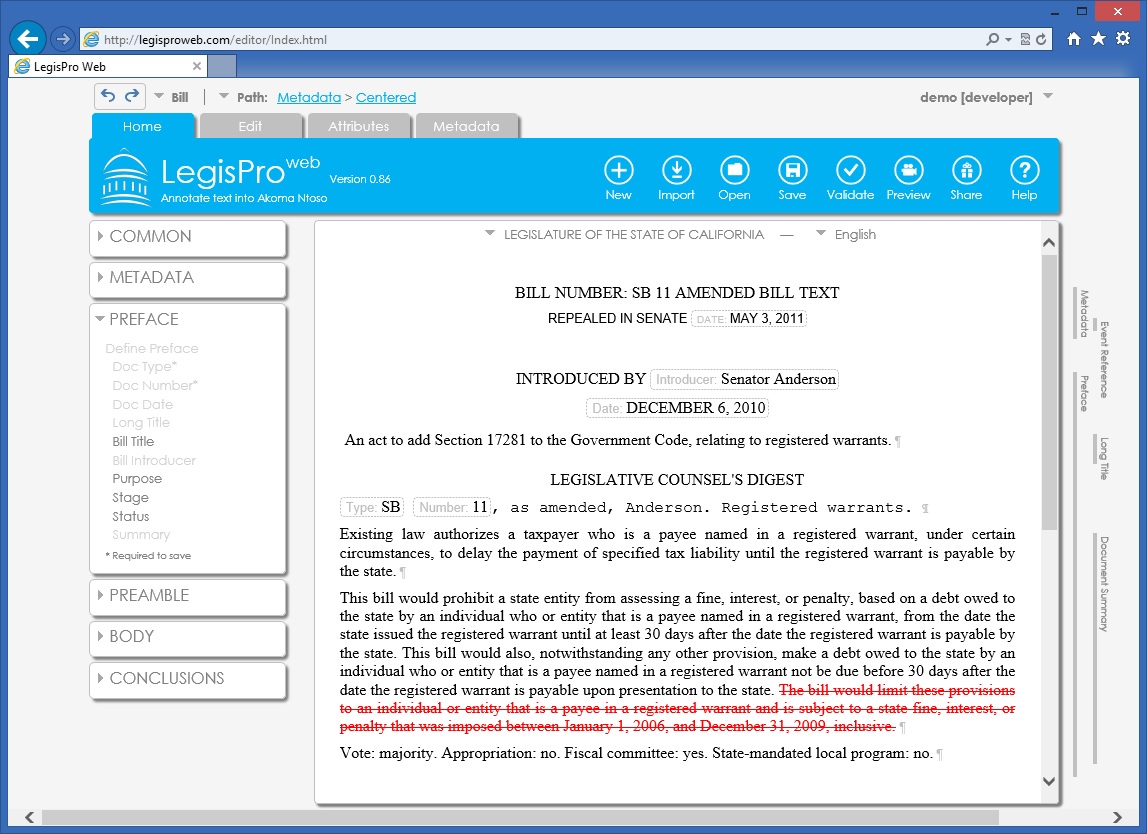
 Input Form
Input Form Validation Results
Validation Results