For the past two weeks I’ve been in Italy attending the LEX Summer School and Akoma Ntoso Developer’s Workshop at the Ravenna campus of the University of Bologna. This is my eighth summer school in Ravenna and my tenth overall LEX Summer School including the two U.S. editions. It’s always one of the highlights of my year.
With Akoma Ntoso as a standard now all but completed, a product about to debut, and a couple Akoma Ntoso projects to our name, I thought it would be a good time to reflect how far we have come. Bill Gates once said “Most people overestimate what they can do in one year and underestimate what they can do in 10 years.” This is a case of that. At times, the progress is frustratingly slow and arduous, but when you look back how far we’ve come in 8 years, we’ve made pretty good progress.
When I arrived at the first summer school I attended back in 2010, I had never heard of Akoma Ntoso — let alone learned how to pronounce it. A lot of the discussion still revolved around whether using purpose-built XML tools or re-purposing office productivity software was the way to go. Did the world really need Akoma Ntoso or was Open Office’s XML formats adequate? What about Microsoft’s Office Open XML? Was it an alternative?
We don’t discuss that anymore — the answer is obvious. As Luca Cervone commented to me, all of a sudden the other approaches look so old-fashioned. In fact, the presentations that did still use that approach were apologetic that their decisions dated back to the early 2000s when the answer was less clear.
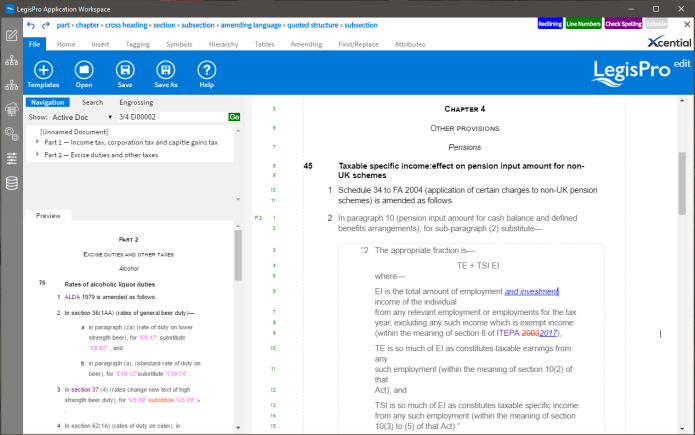
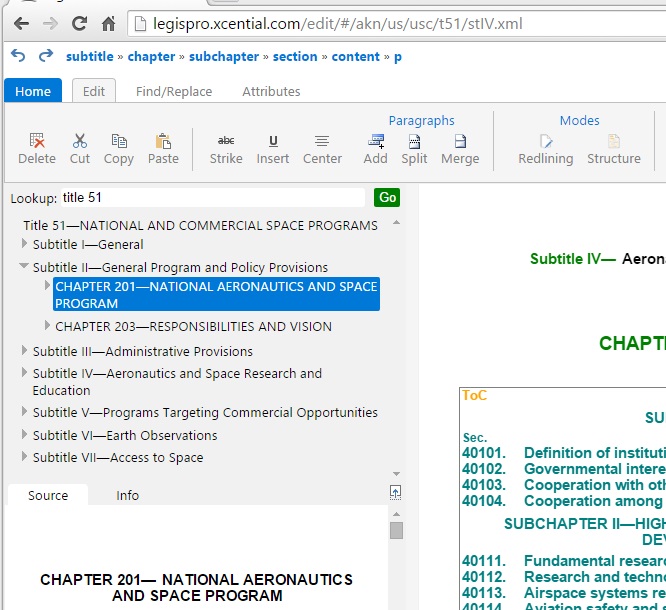
What we now see is the value of putting data first and paper second. Making paper take the back seat in order to take advantage of the inherent power of treating legislation as data is now clearly the way to go. We see this in all the innovative capabilities that were on display — from the advanced amending tools we’ve worked with the UK and Scottish Parliaments to develop, the rich ontology support tools being developed in several projects, to the various comparison and analysis capabilities that were on show. XML enables all of these capabilities, in ways that other approaches simply cannot.
Another change in the eight years is the extent to which Akoma Ntoso has been embraced, particularly in Europe:
- In April of this year, the Chief Executive Board of the United Nations approved the use of Akoma Ntoso as the documentation standard throughout the entire system after a detailed analysis. (Akoma Ntoso began as a project of the UN Department of Economic and Social Affairs (UN/DESA) a decade ago).
- Numerous projects at both the European Parliament and European Commission are now based on Akoma Ntoso, although perhaps in a bit of a disjoint manner.
- The project I’ve devoted a lot of my life to over the past two years at the U.K. and Scottish Parliaments is committed to Akoma Ntoso. You can watch a video of an early version here.
- The Italian Senate is adopting Akoma Ntoso to some extent, and the Italian Chamber of Deputies are considering following suit.
- There are projects underway in Switzerland and South America to adopt Akoma Ntoso.
- Even the U.S. House of Representatives has a prior commitment to support Akoma Ntoso in some way.
This is all very good progress and much more is simmering in the background.
One of my goals at this LEX Summer School was to start laying the seeds for an open framework API that would allow interoperable plugins to be developed that work with all Akoma Ntoso-based platforms. Here, Luca surprised me by showing the new open source Akomando toolkit. This is a JavaScript toolkit, to be made available via NPM, GitHub, and other means shortly, that will provide the basic utilities one needs to easily process XML. As the LIME editor and Xcential’s LegisPro are largely technologically aligned on modern and open web technologies, this toolkit is a natural fit for both applications. I think this is a very exciting development and one we plan to take advantage of as soon as possible.
So, all in all, not bad. Now it’s time to start building on that momentum. We have lots of ideas percolating that will be revealed in the months to come. I’m looking forward to doing another retrospective at the ten year mark.
 Later this week, Xcential will be announcing and showing the latest version of “Sunrise” version of LegisPro, at both
Later this week, Xcential will be announcing and showing the latest version of “Sunrise” version of LegisPro, at both