A couple weeks ago, I was in Ravenna, Italy at the LEX Summer School and follow-on Developer’s Workshop. There, the topic of a semantic web came up a lot. Despite cooling in the popular press in recent years, I’m still a big believer in the idea. The problem with the semantic web is that few people actually get it. At this point, it’s such an abstract idea that people invariably jump to the closest analog available today and mistake it for that.
Tim Berners-Lee (@timberners_lee), the inventor of the web and a big proponent of linked data, has suggested a five star deployment scheme for achieving open data — and what ultimately will be a semantic web. His chart can be thought of as a roadmap for how to get there.
Take a look at today’s Data.gov website. Everybody knows the problem with it — it’s a pretty wrapper around a dumping ground of open data. There are thousands and thousands of data sets available on a wide range of interesting topics. But, there is no unifying data model behind all these data dumps. Sometimes you’re directed to another pretty website that, while well-intentioned, hides the real information behind the decorations. Sometimes you can get a simple text file. If you’re lucky, you might even find the information in some more structured format such as a spreadsheet or XML file. Without any unifying model and with much of the data intended as downloads rather than as an information service, this is really still Tim’s first star of open data — even though some of the data is provided as spreadsheets or open data formats. It’s a good start, but there’s an awful long way to go.
So let’s imagine that a better solution is desired, providing information services, but keeping it all modest by using off-the-shelf technology that everyone is familiar with. Imagine that someone with the authority to do so, takes the initiative to mandate that henceforth, all government data will be produced as Excel spreadsheets. Every memo, report, regulation, piece of legislation, form that citizens fill out, and even the U.S. Code will be kept in Excel spreadsheets. Yes, you need to suspend disbelief to imagine this — the complications that would result would be incredibly tough to solve. But, imagine that all those hurdles were magically overcome.
What would it mean if all government information was stored as spreadsheets? What would be possible if all that information was available throughout the government in predictable and permanent locations? Let’s call the system that would result the Government Information Storehouse – a giant information repository for information regularized as Excel spreadsheets. (BTW, this would be the future of government publishing once paper and PDFs have become relics of the past.)
How would this information look? Think about a piece of legislation, for instance. Each section of the bill might be modeled as a single row in the spreadsheet. Every provision in that section would be it’s own spreadsheet cell (ignoring hierarchical considerations, etc.) Citations would turn into cell references or cell range references. Amending formulas, such as “Section 1234 of Title 10 is amended by…” could be expressed as a literal formula — a spreadsheet formula. It would refer to the specific cell in the appropriate U.S. Code Title and contain programmatic instructions for how to perform the amendment. In short, lots of once complex operations could be automated very efficiently and very precisely. Having the power to turn all government information into a giant spreadsheet has a certain appeal — even if it requires quite a stretch of the imagination.
Now imagine what it would mean if selected parts of this information were available to the public as these spreadsheets – in a regularized and permanent way — say Data.gov 2.0 or perhaps, more accurately, as Info.gov. Think of all the spreadsheet applications that would be built to tease out knowledge from the information that the government is providing through their information portal. Having the ability to programmatically monitor the government without having to resort to complex measures to extract the information would truly enable transparency.
At this point, while the linkages and information services give us some of the attributes of Tim’s four and five star open data solutions, but our focus on spreadsheet technology has left us with a less than desirable two star system. Besides, we all know that having the government publish everything as Excel spreadsheets is absurd. Not everything fits conveniently into a spreadsheet table to say nothing of the scalability problems that would result. I wouldn’t even want to try putting Title 42 of the U.S. Code into an Excel spreadsheet. So how do we really go about achieving this sort of open data and the efficiencies it enables — both inside and outside of government?
In order to realize true four and five star solutions, we need to quickly move on to fulfilling all the parts of Tim’s five star chart. In his chart, a three star solution replaces Excel spreadsheets with an open data format such as a comma separated file. I don’t actually care for this ordering because it sacrifices much to achieve the goal of having neutral file formats — so lets move on to full four and five star solutions. To get there, we need to become proficient in the open standards that exist and we must strive to create ones where they’re missing. That’s why we work so hard on the OASIS efforts to develop Akoma Ntoso and citations into standards for legal documents. And when we start producing real information services, we must ensure that the linkages in the information (those links and formulas I wrote about earlier), exist to the best extent possible. It shouldn’t be up to the consumer to figure out how a provision in a bill relates to a line item in some budget somewhere else — that linkage should be established from the get-go.
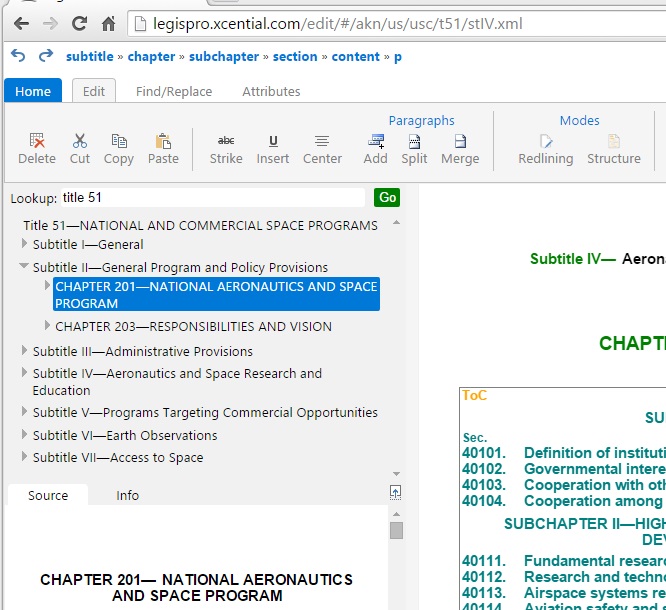
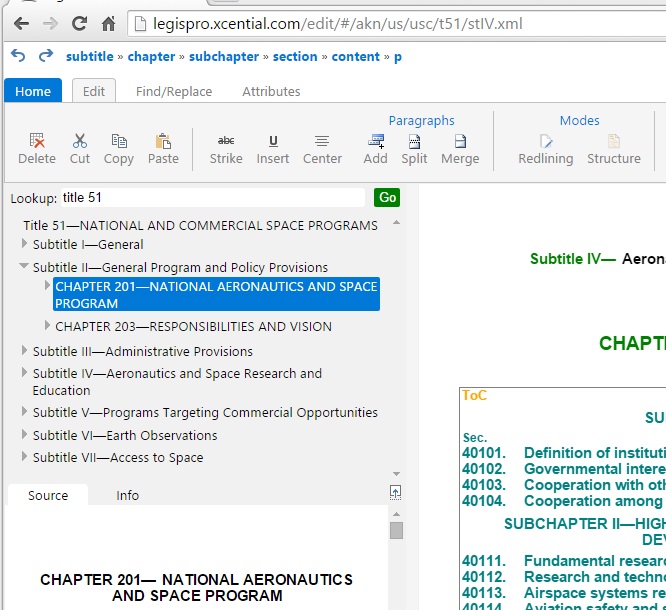
We’re working on a number of core pieces of technology to enable this vision and get to full five star open data. We integrating XML repositories and SQL databases into our architectures to give us the information storehouse I mentioned earlier. We’re building resolver technology that allows us to create and manage permanent linkages. These linkages can be as simple as citation references or as complex as instructions to extract from or make modifications to other information sources. Think of our resolver technology as akin to the engine in Excel than handles cell or range references, arithmetic formulas, and database lookups. And finally, we’re building editors that will resemble word processors in usage, but will allow complex sets of information to be authored and later modified. These editors will have many of the sophisticated capabilities such as track changes that you might see in a modern word processor, but underneath you will find a complex structured model rather than the ad hoc data structures of a word processor.
Building truly open data is going to be a challenging but exciting journey. The solutions that are in place today are a very primitive first step. Many new standards and technologies still need to be developed. But, we’re well on our way.